Concept #032
ArchitectureClean Architecture
- architecture
- domain-driven-design
- programmation
Le problème : quand tout est mélangé
Imaginez une application e-commerce classique. La logique de calcul du prix se trouve dans un composant React. L'envoi d'un email de confirmation est appelé directement depuis un contrôleur Express. La validation des stocks interroge la base de données depuis l'interface utilisateur.
Ce scénario est courant, et il est catastrophique.
Le couplage fort entre l'UI, la logique métier et la base de données crée une masse de code impossible à faire évoluer. Changer de base de données oblige à toucher aux règles métier. Tester un calcul de prix exige une connexion active à PostgreSQL. Migrer vers une nouvelle interface impose de réécrire la logique de commande.
Le code devient rigide. Chaque modification casse quelque chose ailleurs. Les développeurs ont peur de toucher au code existant. Les tests sont rares, lents, ou absents. Le projet ralentit, puis s'arrête.
Robert C. Martin (Uncle Bob) a formalisé une réponse à ce problème : la Clean Architecture.
La règle de dépendance : une seule loi à retenir
La Clean Architecture organise le code en couches concentriques, comme un oignon. Chaque couche ne peut dépendre que des couches plus internes, jamais des couches externes.
La règle de dépendance : les dépendances pointent toujours vers l'intérieur.
Le code métier, au centre, ne connaît pas la base de données. Il ne connaît pas Express, ni React, ni PostgreSQL. Il ne sait même pas si des données sont stockées dans un fichier CSV ou dans un cluster MongoDB. Il ne manipule que des abstractions qu'il a lui-même définies.
C'est cette règle, et uniquement celle-ci, qui rend l'architecture propre. Tout le reste en découle.
Les quatre couches
Entities (le noyau)
Les entités représentent les concepts fondamentaux du domaine métier. Ce sont les règles et les structures qui existeraient même sans informatique. Dans un système de gestion de commandes, Order, Product et Customer sont des entités.
Elles encapsulent les règles métier les plus générales : une commande ne peut pas avoir un montant négatif, un produit doit avoir un identifiant unique. Ces règles ne changent que si les règles métier elles-mêmes changent, jamais pour des raisons techniques.
Use Cases (les cas d'usage)
Les use cases orchestrent le flux de données vers et depuis les entités pour accomplir un objectif précis : CreateOrder, CancelOrder, GetOrderHistory. Ils contiennent la logique applicative : ce que le système fait.
Un use case ne sait pas d'où viennent les données (HTTP, CLI, message queue) ni où elles sont stockées (SQL, NoSQL, cache). Il parle uniquement à des interfaces.
Interface Adapters (les adaptateurs)
Cette couche convertit les données entre le format des use cases et le format du monde extérieur. Les contrôleurs HTTP, les présenteurs, les repositories concrets vivent ici. Un contrôleur Express transforme une requête HTTP en appel de use case. Un repository PostgreSQL implémente l'interface de persistance définie par le domaine.
Frameworks & Drivers (la périphérie)
La couche la plus externe contient les détails techniques : Express, React, PostgreSQL, Redis, le système de fichiers. Ces éléments sont interchangeables. Changer de framework ne devrait pas affecter un seul use case.
Exemple TypeScript : un use case sans dépendances externes
Voici un use case CreateOrder qui respecte strictement la règle de dépendance. Il ne connaît ni Express, ni Prisma, ni aucune librairie externe.
// Entité du domaine
interface Order {
id: string;
customerId: string;
items: OrderItem[];
totalAmount: number;
status: "pending" | "confirmed" | "cancelled";
}
interface OrderItem {
productId: string;
quantity: number;
unitPrice: number;
}
// Interfaces définies par le domaine (jamais par l'extérieur)
interface OrderRepository {
save(order: Order): Promise<void>;
findById(id: string): Promise<Order | null>;
}
interface ProductCatalog {
getPrice(productId: string): Promise<number>;
}
interface NotificationService {
sendOrderConfirmation(orderId: string, customerId: string): Promise<void>;
}
// Le use case : aucune import externe
class CreateOrderUseCase {
constructor(
private orderRepository: OrderRepository,
private productCatalog: ProductCatalog,
private notificationService: NotificationService
) {}
async execute(input: {
customerId: string;
items: { productId: string; quantity: number }[];
}): Promise<string> {
// Calcul du montant via le catalogue (abstrait)
const itemsWithPrice = await Promise.all(
input.items.map(async (item) => ({
productId: item.productId,
quantity: item.quantity,
unitPrice: await this.productCatalog.getPrice(item.productId),
}))
);
const totalAmount = itemsWithPrice.reduce(
(sum, item) => sum + item.unitPrice * item.quantity,
0
);
// Règle métier : une commande doit avoir un montant positif
if (totalAmount <= 0) {
throw new Error("Le montant de la commande doit être positif");
}
const order: Order = {
id: crypto.randomUUID(),
customerId: input.customerId,
items: itemsWithPrice,
totalAmount,
status: "confirmed",
};
await this.orderRepository.save(order);
await this.notificationService.sendOrderConfirmation(order.id, order.customerId);
return order.id;
}
}CreateOrderUseCase ne contient aucun import vers une librairie externe. Il ne sait pas si OrderRepository est implémenté avec Prisma, Drizzle, ou un simple tableau en mémoire. C'est exactement ce que la règle de dépendance exige.
L'isolation via Ports & Adapteurs
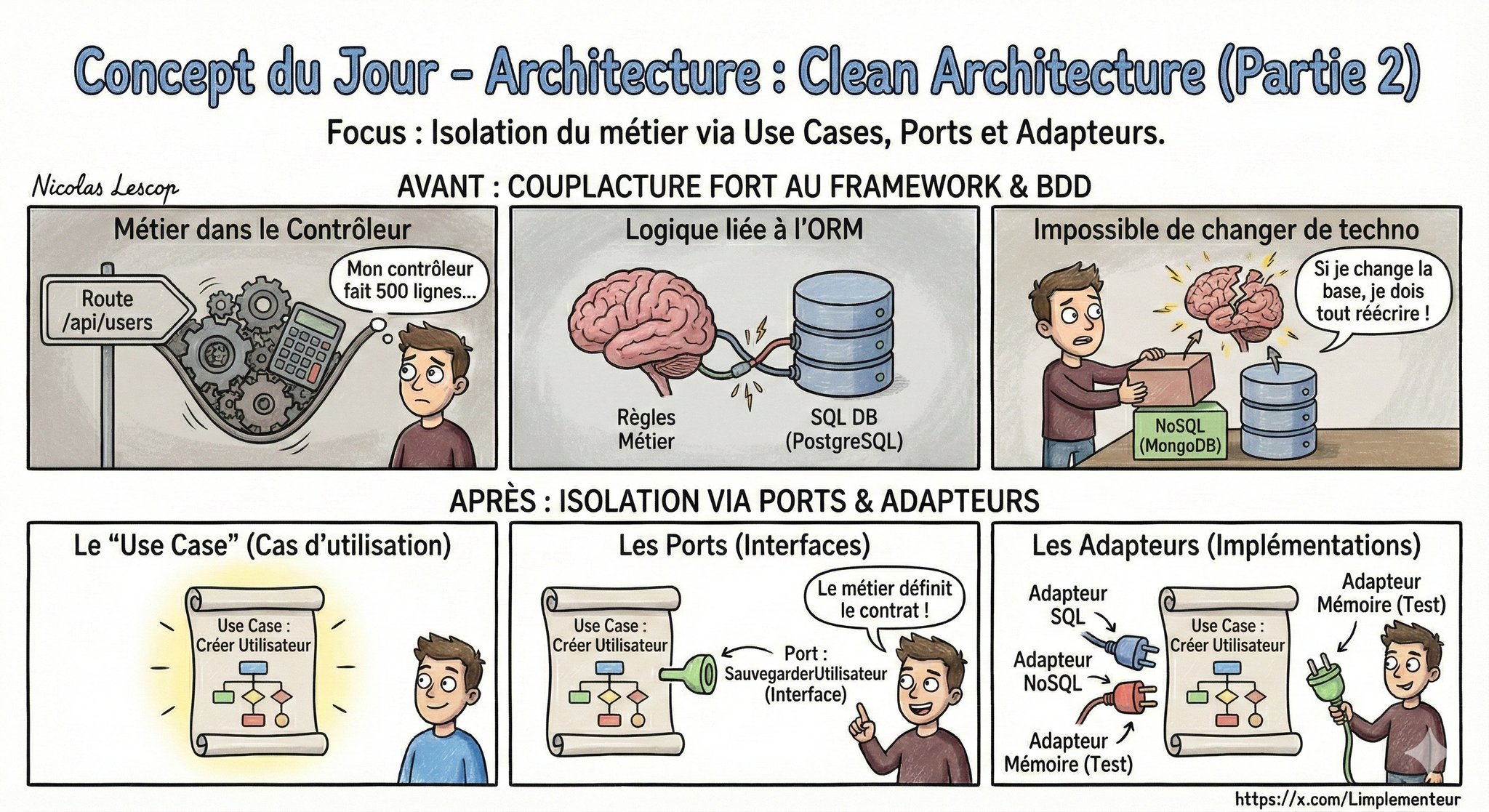
Comment rendre le métier agnostique de la base de données ? Le Use Case définit un contrat (Port/Interface). L'infrastructure s'y adapte via une implémentation concrète. Résultat : on peut changer de techno sans casser la logique métier.
La Clean Architecture et l'architecture hexagonale (Ports & Adapters, Alistair Cockburn) partagent la même idée centrale : isoler le domaine métier du monde technique via des interfaces.
Dans la terminologie hexagonale, les interfaces définies par le domaine (OrderRepository, NotificationService) sont des ports. Les implémentations concrètes (le repository Prisma, le service d'email SendGrid) sont des adaptateurs.
// Le Port : défini par le domaine
interface OrderRepository {
save(order: Order): Promise<void>;
findById(id: string): Promise<Order | null>;
}
// L'Adapteur : implémentation concrète dans l'infra
class PrismaOrderRepository implements OrderRepository {
async save(order: Order): Promise<void> {
await prisma.order.create({ data: order });
}
async findById(id: string): Promise<Order | null> {
return prisma.order.findUnique({ where: { id } });
}
}
// Demain, on change de BDD sans toucher au métier
class MongoOrderRepository implements OrderRepository {
async save(order: Order): Promise<void> {
await mongoCollection.insertOne(order);
}
async findById(id: string): Promise<Order | null> {
return mongoCollection.findOne({ id });
}
}Le use case ne sait pas — et ne doit pas savoir — quelle implémentation est utilisée. Il parle au port, jamais à l'adapteur. C'est cette inversion de dépendance qui rend le système flexible.
Le super-pouvoir : la testabilité
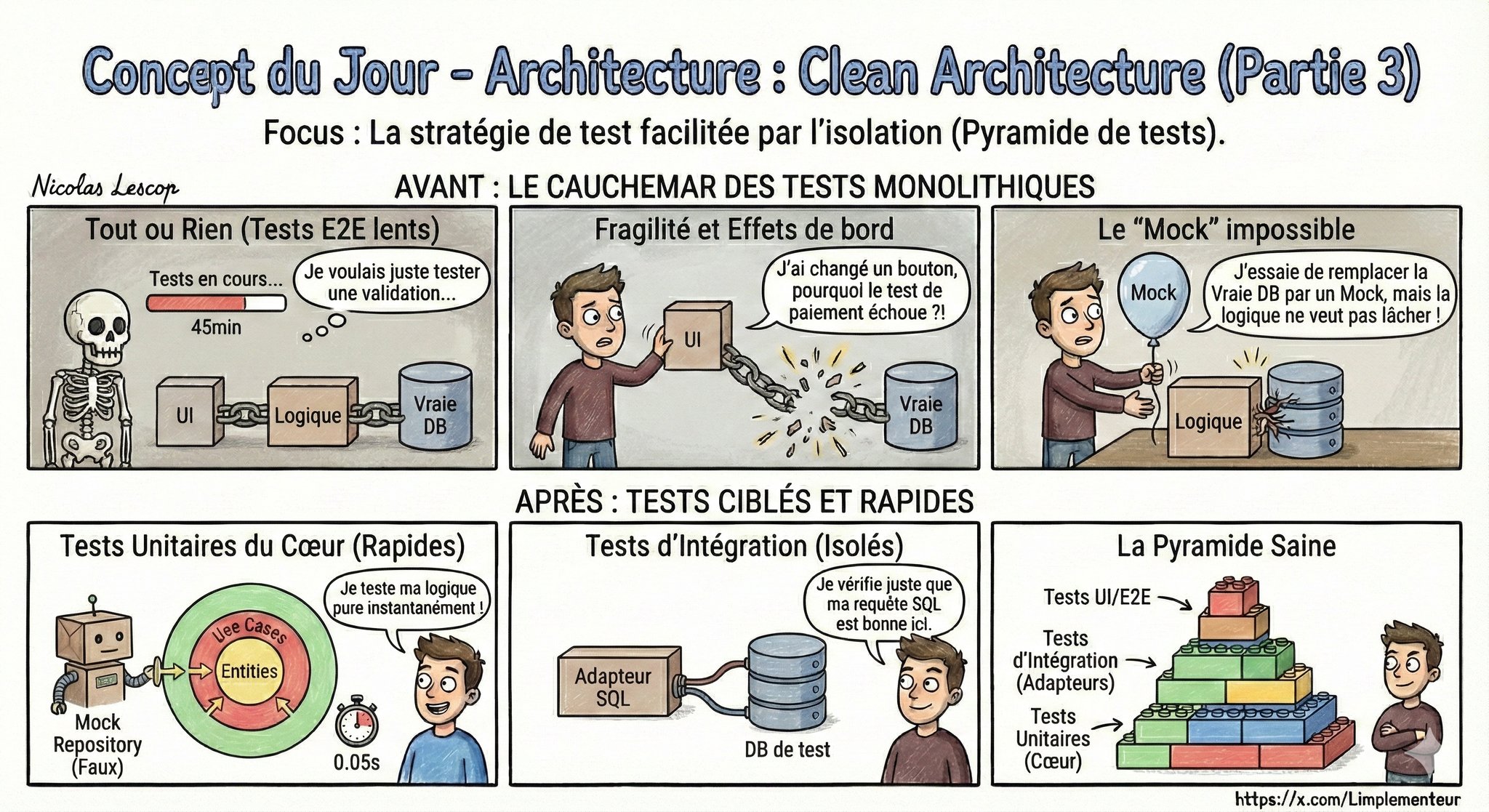
Fini les tests lents de bout en bout pour valider une règle de gestion. Grace à l'isolation, on peut "mocker" l'extérieur. On valide le coeur avec des tests unitaires ultra-rapides et fiables. C'est la base d'une pyramide de tests solide.
Puisque CreateOrderUseCase ne dépend que d'interfaces, il peut être testé avec des doublures (mocks ou fakes) injectées à la place des implémentations réelles :
// Test unitaire : aucune base de données, aucune latence réseau
test("crée une commande et envoie une notification", async () => {
const fakeRepository: OrderRepository = {
save: vi.fn().mockResolvedValue(undefined),
findById: vi.fn(),
};
const fakeCatalog: ProductCatalog = {
getPrice: vi.fn().mockResolvedValue(29.99),
};
const fakeNotification: NotificationService = {
sendOrderConfirmation: vi.fn().mockResolvedValue(undefined),
};
const useCase = new CreateOrderUseCase(
fakeRepository,
fakeCatalog,
fakeNotification
);
const orderId = await useCase.execute({
customerId: "customer-1",
items: [{ productId: "product-1", quantity: 2 }],
});
expect(orderId).toBeDefined();
expect(fakeRepository.save).toHaveBeenCalledOnce();
expect(fakeNotification.sendOrderConfirmation).toHaveBeenCalledWith(
orderId,
"customer-1"
);
});Ce test s'exécute en millisecondes. Il ne nécessite aucune infrastructure. Il teste précisément la logique métier, sans bruit technique. Multipliez ce pattern sur l'ensemble d'une application, et vous obtenez une suite de tests rapide, stable, et qui donne confiance pour refactoriser.
En résumé
La Clean Architecture n'est pas une contrainte bureaucratique. C'est une réponse pragmatique au couplage fort qui ralentit les équipes. Une seule règle suffit à retenir : les dépendances pointent toujours vers l'intérieur.
- Partie 1 : Séparez les préoccupations en couches concentriques. Le code métier ne dépend jamais de l'extérieur.
- Partie 2 : Isolez le métier via des Ports (interfaces) et des Adapteurs (implémentations). Changez de techno sans casser la logique.
- Partie 3 : Testez le coeur en injectant des doublures. Des tests rapides, fiables, sans infrastructure.
Le code métier définit ses propres interfaces. Le monde extérieur s'y adapte, jamais l'inverse. Le résultat : un noyau testable, portable, et pérenne, indépendant des modes technologiques.